NPTEL Deep Learning – IIT Ropar Week 9 Assignment Answers 2025
1. What is the disadvantage of using Hierarchical Softmax?
- It requires more memory to store the binary tree
- It is slower than computing the softmax function directly
- It is less accurate than computing the softmax function directly
- It is more prone to overfitting than computing the softmax function directly
Answer :- For Answers Click Here
2. Consider the following corpus: “AI driven user experience optimization. Perception of AI decision making speed. Intelligent interface adaptation system. AI system engineering for enhanced processing efficiency”. What is the size of the vocabulary of the above corpus?
- 18
- 20
- 22
- 19
Answer :-
3. We add incorrect pairs into our corpus to maximize the probability of words that occur in the same context and minimize the probability of words that occur in different contexts. This technique is called:
- Negative sampling
- Hierarchical softmax
- Contrastive estimation
- Glove representations
Answer :-
4. Let X be the co-occurrence matrix such that the (i,j)-th entry of X captures the PMI between the i -th and j -th word in the corpus. Every row of X corresponds to the representation of the i -th word in the corpus. Suppose each row of X is normalized (i.e., the L2 norm of each row is 1) then the (i,j) -th entry of XXT captures the:
- PMI between word i and word j
- Euclidean distance between word i and word j
- Probability that word i
- Cosine similarity between word i
Answer :-
5. Suppose that we use the continuous bag of words (CBOW) model to find vector representations of words. Suppose further that we use a context window of size 3 (that is, given the 3 context words, predict the target word P(wt(wi,wj,wk))). The size of word vectors (vector representation of words) is chosen to be 100 and the vocabulary contains 20,000 words. The input to the network is the one-hot encoding (also called 1-of-V encoding) of word(s). How many parameters (weights), excluding bias, are there in Wword ? Enter the answer in thousands. For example, if your answer is 50,000, then just enter 50.
Answer :- For Answers Click Here
6. You are given the one hot representation of two words below:
GEMINI=[1, 0, 0, 0, 1], CLAUDE=[0, 0, 0, 1, 0]
What is the Euclidean distance between GEMINI and CLAUDE?
Answer :-
7. Let count(w,c) be the number of times the words w and c appear together in the corpus (i.e., occur within a window of few words around each other). Further, let count(w) and count(c) be the total number of times the word w and c appear in the corpus respectively and let N be the total number of words in the corpus. The PMI between w and c is then given by:
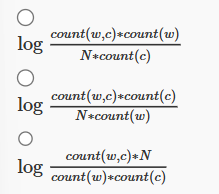
Answer :-
8. Consider a skip-gram model trained using hierarchical softmax for analyzing scientific literature. We observe that the word embeddings for Neuron’ andBrain’ are highly similar. Similarly, the embeddings for Synapse’ andBrain’ also show high similarity. Which of the following statements can be inferred?
- Neuron’ andBrain’ frequently appear in similar contexts
- The model’s learned representations will indicate a high similarity between ‘Neuron’ and Synapse’
- The model’s learned representations will not show a high similarity betweenNeuron’ and Synapse’
- According to the model’s learned representations,Neuron’ and `Brain’ have a low cosine similarity
Answer :-
9. Suppose we are learning the representations of words using Glove representations. If we observe that the cosine similarity between two representations vi and vj for words ‘i’ and ‘j ‘ is very high. which of the following statements is true?( parameter bi = 0.02 and bj = 0.07)
- Xij=0.04
- Xij=0.17
- Xij=0
- Xij=0.95
Answer :-
10. Which of the following is an advantage of using the skip-gram method over the bag-of-words approach?
- The skip-gram method is faster to train
- The skip-gram method performs better on rare words
- The bag-of-words approach is more accurate
- The bag-of-words approach is better for short texts
Answer :- For Answers Click Here

