NPTEL Deep Learning – IIT Ropar Week 4 Assignment Answers 2025
1. Using the Adam optimizer with β1=0.9, β2=0.999, and ϵ=10−8, what would be the bias-corrected first moment estimate after the first update if the initial gradient is 4?
- 0.4
- 4.0
- 3.6
- 0.44
Answer :- For Answers Click Here
2. In a mini-batch gradient descent algorithm, if the total number of training samples is 50,000 and the batch size is 100, how many iterations are required to complete 10 epochs?
- 5,000
- 50,000
- 500
- 5
Answer :-
3. In a stochastic gradient descent algorithm, the learning rate starts at 0.1 and decays exponentially with a decay rate of 0.1 per epoch. What will be the learning rate after 5 epochs?
Answer :-
4. In the context of Adam optimizer, what is the purpose of bias correction?
- To prevent overfitting
- To speed up convergence
- To correct for the bias in the estimates of first and second moments
- To adjust the learning rate
Answer :-
5. The figure below shows the contours of a surface.
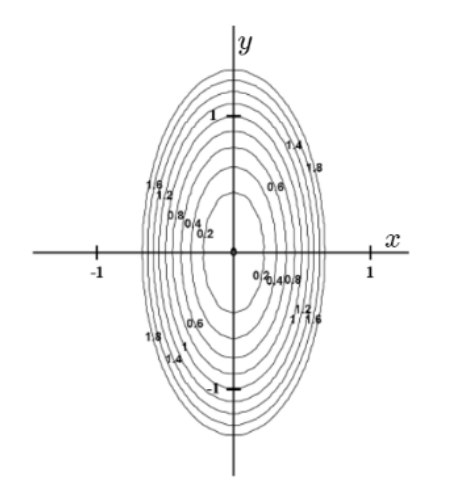
Suppose that a man walks, from -1 to +1, on both the horizontal (x) axis and the vertical (y) axis. The statement that the man would have seen the slope change rapidly along the x-axis than the y-axis is,
- True
- False
- Cannot say
Answer :-
6. What is the primary benefit of using Adagrad compared to other optimization algorithms?
- It converges faster than other optimization algorithms.
- It is more memory-efficient than other optimization algorithms.
- It is less sensitive to the choice of hyperparameters(learning rate).
- It is less likely to get stuck in local optima than other optimization algorithms.
Answer :- For Answers Click Here
7. What are the benefits of using stochastic gradient descent compared to vanilla gradient descent?
- SGD converges more quickly than vanilla gradient descent.
- SGD is computationally efficient for large datasets.
- SGD theoretically guarantees that the descent direction is optimal.
- SGD experiences less oscillation compared to vanilla gradient descent.
Answer :-
8. What is the role of activation functions in deep learning?
- Activation functions transform the output of a neuron into a non-linear function, allowing the network to learn complex patterns.
- Activation functions make the network faster by reducing the number of iterations needed for training.
- Activation functions are used to normalize the input data.
- Activation functions are used to compute the loss function.
Answer :-
9. What is the advantage of using mini-batch gradient descent over batch gradient descent?
- Mini-batch gradient descent is more computationally efficient than batch gradient descent.
- Mini-batch gradient descent leads to a more accurate estimate of the gradient than batch gradient descent.
- Mini batch gradient descent gives us a better solution.
- Mini-batch gradient descent can converge faster than batch gradient descent.
Answer :-
10. In the Nesterov Accelerated Gradient (NAG) algorithm, the gradient is computed at:
- The current position
- A “look-ahead” position
- The previous position
- The average of current and previous positions
Answer :- For Answers Click Here

