NPTEL Reinforcement Learning Week 4 Assignment Answers 2025
1. State True/False
The state transition graph for any MDP is a directed acyclic graph.
- True
- False
Answer :- For Answers Click Here
2. Consider the following statements:
(i) The optimal policy of an MDP is unique.
(ii) We can determine an optimal policy for a MDP using only the optimal value function (v∗) ,without accessing the MDP parameters.
(iii) We can determine an optimal policy for a given MDP using only the optimal q-valuefunction (q∗), without accessing the MDP parameters.
Which of these statements are true?
- Only (ii)
- Only (iii)
- Only (i), (ii)
- Only (i), (iii)
- Only (ii), (iii)
Answer :-
3. Which of the following is a benefit of using RL algorithms for solving MDPs?
- They do not require the state of the agent for solving a MDP.
- They do not require the action taken by the agent for solving a MDP.
- They do not require the state transition probability matrix for solving a MDP.
- They do not require the reward signal for solving a MDP.
Answer :-
4. Consider the following equations:
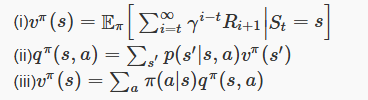
Which of the above are correct?
- Only (i)
- Only (i), (ii)
- Only (ii), (iii)
- Only (i), (iii)
- (i), (ii), (iii)
Answer :-
5. State True/False
While solving MDPs, in case of discounted rewards, the value of γ (discount factor) cannot affect the optimal policy.
- True
- False
Answer :-
6. Consider the following statements for a finite MDP (I is an identity matrix with dimensions |S|×|S|(S is the set of all states) and Pπ is a stochastic matrix):
(i) MDP with stochastic rewards may not have a deterministic optimal policy.
(ii) There can be multiple optimal stochastic policies.
(iii) If 0≤γ<1, then rank of the matrix I−γPπ is equal to |S|.
(iv) If 0≤γ<1, then rank of the matrix I−γPπis less than |S|.
Which of the above statements are true?
- Only (ii), (iii)
- Only (ii), (iv)
- Only (i), (iii)
- Only (i), (ii), (iii)
Answer :- For Answers Click Here
7. Consider an MDP with 3 states A, B, C. From each state, we can go to either of the two states, i.e, from state A, we can perform 2 actions, that lead to state B and C respectively.The rewards for all the transitions are: r(A,B)=2 (reward if we go from A to B), r(B,A)=5,r(B,C)=7,r(C,B)=10,r(A,C)=1,r(C,A)=12.,The discount factor is 0.7. Find the value function for the policy given by:π(A)=C (if we are in state A, we choose the action to go to C), π(B)=A
and π(C)=B([vπ(A),vπ(B),vπ(C)]).
- [10.2, 16.7, 20.2]
- [14.2, 16.5, 15.1]
- [15.9, 16.1, 21.3]
- [12.2, 6.2, 14.5]
Answer :-
8. Suppose x is a fixed point for the function A,y is a fixed point for the function B, and x=BA(x)
, where BA is the composition of B and A . Consider the following statements:
(i) x is a fixed point for B
(ii) x=y
(iii) BA(y)=y
Which of the above must be true?
- Only (i)
- Only (ii)
- Only (i), (ii)
- (i), (ii), (iii)
Answer :-
9. Which of the following is not a valid norm function? (x is a D dimensional vector)
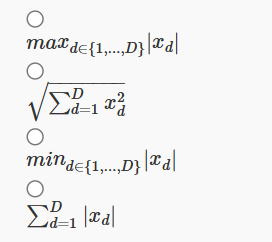
Answer :-
10. Which of the following is a contraction mapping in any norm?
- T([x1,x2])=[0.5x1,0.5x2]
- T([x1,x2])=[2x1,2x2]
- T([x1,x2])=[2x1,3x2]
- T([x1,x2])=[x1+x2,x1−x2]
Answer :- For Answers Click Here

