NPTEL Reinforcement Learning Week 6 Assignment Answers 2025
1. Which of the following are true?
- Dynamic programming methods use full backups and bootstrapping.
- Temporal-Difference methods use sample backups and bootstrapping.
- Monte-Carlo methods use sample backups and bootstrapping.
- Monte-Carlo methods use full backups and no bootstrapping
Answer :- For Answers Click Here
2. Consider the following statements:
(i)TD(0) methods uses unbiased sample of the return.
(ii)TD(0) methods uses a sample of the reward from the distribution of rewards.
(iii) TD(0) methods uses the current estimate of value function.
Which of the above statements is/are true?
- (i), (ii)
- (i),(iii)
- (ii), (iii)
- (i), (ii), (iii)
Answer :-
3. Consider an MDP with two states A and B. Given the single trajectory shown below (in the pattern of state, reward, next state…), use on-policy TD(0) updates to make estimates for the values of the 2 states.
A, 3, B, 2, A, 5, B, 2, A, 4, END
Assume a discount factor γ=1, a learning rate α=1 and initial state-values of zero. What are the estimated values for the 2 states at the end of the sampled trajectory? (Note: You are not asked to compute the true values for the two states.)
- V(A)=2,V(B)=10
- V(A)=8,V(B)=7
- V(A)=4,V(B)=12
- V(A)=12,V(B)=7
Answer :-
4. Which of the following statements are true for SARSA?
- It is a TD method.
- It is an off-policy algorithm.
- It uses bootstrapping to approximate full return.
- It always selects the greedy action choice.
Answer :-
5. Assertion: In Expected-SARSA, we may select actions off-policy.
Reason: In the update rule for Expected-SARSA, we use the estimated expected value of the next state under the policy π rather than directly using the estimated value of the next state that is sampled on-policy.
- Assertion and Reason are both true and Reason is a correct explanation of Assertion.
- Assertion and Reason are both true and Reason is not a correct explanation of Assertion.
- Assertion is true but Reason is false.
- Assertion is false but Reason is true.
Answer :- For Answers Click Here
6. Assertion: Q-learning can use asynchronous samples from different policies to update Q values.
Reason: Q-learning is an off-policy learning algorithm.
- Assertion and Reason are both true and Reason is a correct explanation of Assertion.
- Assertion and Reason are both true and Reason is not a correct explanation of Assertion.
- Assertion is true but Reason is false.
- Assertion is false but Reason is true.
Answer :-
7. Suppose, for a 2 player game that we have modeled as an MDP, instead of learning a policy over the MDP directly, we separate the deterministic and stochastic result of playing an action to create ‘after-states’ (as discussed in the lectures). Consider the following statements:
(i) The set of states that make up ‘after-states’ may be different from the original set of states for the MDP. (ii) The set of ‘after-states’ could be smaller than the original set of states for the MDP.
Which of the above statements is/are True?
- Only (i)
- Only (ii)
- Both (i) and (ii)
- Neither (i) nor (ii)
Answer :-
8. Assertion: Rollout algorithms take advantage of the policy improvement property.
Reason: Rollout algorithms selects action with the highest estimated values.
- Assertion and Reason are both true and Reason is a correct explanation of Assertion.
- Assertion and Reason are both true and Reason is not a correct explanation of Assertion.
- Assertion is true but Reason is false.
- Assertion and Reason are both false.
Answer :-
9. Consider the environment given below (CliffWorld discussed in lecture):
Suppose we use ϵ -greedy policy for exploration with a value of ϵ = 0.1. Select the correct option(s):
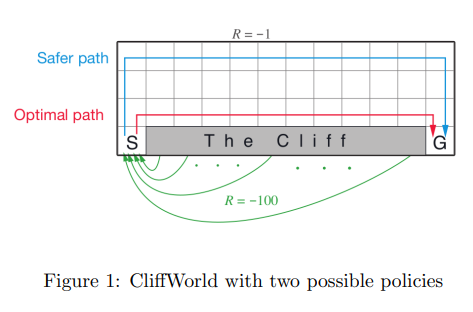
- Q-Learning finds the optimal(red) path.
- Q-Learning finds the safer(blue) path.
- SARSA finds the optimal(red) path.
- SARSA finds the safer(blue) path.
Answer :-
10. Which of the following are True for TD(0) ? (Assume that the environment is truly Markov)
- It uses the full return to update the value of states.
- Both TD(0) and Monte-Carlo policy evaluation converge to the same value function, given a finite number of samples.
- Both TD(0) and Monte-Carlo policy evaluation converge to the same value function, given an infinite number of samples.
- TD error is given by “δ=vnew(st,at)−vold(st,at)”
Answer :- For Answers Click Here

