NPTEL Business Intelligence & Analytics Week 7 Assignment Answers 2025
1. ____________ refers to the process of learning decision trees from training tuples that have class labels.
- Decision tree construction
- Decision tree induction
- Rule-based learning
- Information gain
Answer :-
2. The greedy approach employed by CART for constructing decision trees follows a __________ method.
- Bottom-up recursive divide-and-conquer
- Top-down recursive divide-and-conquer
- Bottom-up non-recursive divide-and-conquer
- Top-down non-recursive divide-and-conquer
Answer :-
3. Which technique combines predictions from several models, each trained on bootstrapped versions of the dataset, to improve generalization?
- Decision tree pruning
- Ridge regression
- Recursive feature elimination
- Bootstrap aggregation (bagging)
Answer :-
4. How does a binary decision tree handle a discrete-valued attribute A during dataset splitting?
- By forming two branches: A ≤ split_point and A > split_point.
- By creating one branch for each distinct value of A. A ∈ SA, where SA
- By applying a test A ∈ SA, where SA is a subset of values of A.
- None of the above
Answer :-
5. In a decision tree for recommending movies, what does each branch represent?
- A movie title
- The outcome of a test, like favourite director
- A test on an attribute, such as user age
- An unknown user preference
Answer :-
6. The primary goal of tree pruning in decision tree algorithms is to by the tree, thus avoiding _________.
- Improve performance, growing, underfitting
- Increase complexity, expanding, overfitting
- Prevent overfitting, simplifying, overfitting
- Enhance accuracy, deepening, training bias
Answer :-
7. In the post-pruning of a decision tree, the leaf node is assigned the most frequent class label among the subtree being replaced.
- True
- False
Answer :-
8. Which of the following best describes how models are handled in the bagging method?
- Weights are assigned randomly
- All models receive equal weight
- Models are weighted based on their performance
- More recent models are given more importance
Answer :-
9. Given two equally represented classes in a dataset, what is the entropy of the system?
- 0
- 1
- Infinite
- -1
Answer :-
10. Which of these statements is incorrect about Random Forests?
- Random forests use bagging and random selection of features at each node to train decision trees.
- A Random Forest model is built from many decision trees, and each tree is trained using different random samples of data and features.
- The number of features chosen at each split is a critical factor in determining the success of the Random Forest.
- Random Forests accuracy is determined by the individual decision trees’ accuracy and their mutual dependence.
Answer :- For Answers Click Here
11. Given the expression,
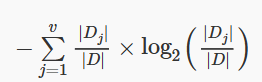
which of the following does it represent?
- Gini(D)
- Gain (A)
- SplitInfoA(D)
- GainRatio(A)
Answer :-
12. Common techniques for handling imbalanced data in classification tasks include_________ , the minority class and _________, the majority class
- Oversampling, Undersampling
- Under sampling, Oversampling
- Oversampling, Random Sampling
- SMOTE, Undersampling
Answer :-
13. Imagine you’re analyzing the purchase behavior of customers on a popular online store during a seasonal sale. You want to assess the Gini indices for customer actions after splitting by the “Purchase Category” feature.
Node 1 (left child): Out of 30 customers, 15 added items to the cart but didn’t purchase (“No Purchase”) & 15 completed their purchase (“Purchase”).
Node 2 (right child): Out of 70 customers, 30 abandoned their cart (“No Purchase”) & 40 went ahead and purchased the items (“Purchase”).
Which option has the correct Gini indices for the child nodes?
- Gini index for Node 1: 0.500, Gini index for Node 2: 0.428
- Gini index for Node 1: 0.375, Gini index for Node 2: 0.370
- Gini index for Node 1: 0.400, Gini index for Node 2: 0.375
- Gini index for Node 1: 0.400, Gini index for Node 2: 0.500
Answer :-
14. In a customer satisfaction prediction model, which of the following is an advantage of decision trees over linear regression?
- Decision trees are less affected by outliers.
- Decision trees are easier to explain and interpret.
- Decision trees require the creation of dummy variables for qualitative predictors.
- Decision trees are more accurate in predicting continuous outcomes.
Answer :-
15. In building a decision tree for classifying customers based on their purchase behaviors, which of the following heuristics are typically used for selecting the best-split criterion?
- Information gain, Gain ratio, Gini impurity
- Information gain, Gini impurity, Residual sum of squares
- Gain ratio, Residual sum of squares, Entropy
- Precision, Gini impurity, Information gain
Answer :- For Answers Click Here

