NPTEL Deep Learning – IIT Ropar Week 8 Assignment Answers 2025
1. What are the challenges associated with using the Tanh(x) activation function?
- It is not zero centered
- Computationally expensive
- Non-differentiable at 0
- Saturation
Answer :- For Answers Click Here
2. Which of the following problems makes training a neural network harder while using sigmoid as the activation function?
- Not-continuous at 0
- Not-differentiable at 0
- Saturation
- Computationally expensive
Answer :-
3. Consider the Exponential ReLU (ELU) activation function, defined as:
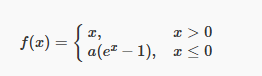
where a≠0. Which of the following statements is true?
- The function is discontinuous at x=0.
- The function is non-differentiable at x=0.
- Exponential ReLU can produce negative values.
- Exponential ReLU is computationally less expensive than ReLU.
Answer :-
4. We have observed that the sigmoid neuron has become saturated. What might be the possible output values at this neuron?
- 0.0666
- 0.589
- 0.9734
- 0.498
- 1
Answer :-
5. What is the gradient of the sigmoid function at saturation?
Answer :-
6. Which of the following are common issues caused by saturating neurons in deep networks?
- Vanishing gradients
- Slow convergence during training
- Overfitting
- Increased model complexity
Answer :- For Answers Click Here
7. Given a neuron initialized with weights w1=0.9, w2=1.7, and inputs x1=0.4, x2=−0.7, calculate the output of a ReLU neuron.
Answer :-
8. Which of the following is incorrect with respect to the batch normalization process in neural networks?
- We normalize the output produced at each layer before feeding it into the next layer
- Batch normalization leads to a better initialization of weights.
- Backpropagation can be used after batch normalization
- Variance and mean are not learnable parameters.
Answer :-
9. Which of the following is an advantage of unsupervised pre-training in deep learning?
- It helps in reducing overfitting
- Pre-trained models converge faster
- It requires fewer computational resources
- It improves the accuracy of the model
Answer :-
10. How can you tell if your network is suffering from the Dead ReLU problem?
- The loss function is not decreasing during training
- A large number of neurons have zero output
- The accuracy of the network is not improving
- The network is overfitting to the training data
Answer :- For Answers Click Here

