NPTEL Introduction to Machine Learning Week 7 Assignment Answers 2025
1. Which of the following statement(s) regarding the evaluation of Machine Learning models is/are true?
- A model with a lower training loss will perform better on a validation dataset.
- A model with a higher training accuracy will perform better on a validation dataset.
- The train and validation datasets can be drawn from different distributions
- The train and validation datasets must accurately represent the real distribution of data
Answer :- For Answers Click Here
2. Suppose we have a classification dataset comprising of 2 classes A and B with 200 and 40 samples respectively. Suppose we use stratified sampling to split the data into train and test sets. Which of the following train-test splits would be appropriate?
- Train-{A:50samples,B:10samples},Test-{A:150samples,B:30samples}
- Train-{A:50samples,B:30samples},Test- {A:150samples,B:10samples}
- Train- {A:150samples,B:30samples},Test- {A:50samples,B:10samples}
- Train- {A:150samples,B:10samples},Test- {A:50samples,B:30samples}
Answer :-
3. Suppose we are performing cross-validation on a multiclass classification dataset with N data points. Which of the following statement(s) is/are correct?
- In k-fold cross-validation, we train k−1 different models and evaluate them on the same test set
- In k-fold cross-validation, we train k different models and evaluate them on different test sets
- In k-fold cross-validation, each fold should have a class-wise proportion similar to the given dataset.
- In LOOCV (Leave-One-Out Cross Validation), we train N different models, using N−1 data points for training each model
Answer :-
4. (Qns 4 to 7) For a binary classification problem we train classifiers and evaluate them to obtain confusion matrices in the following format:
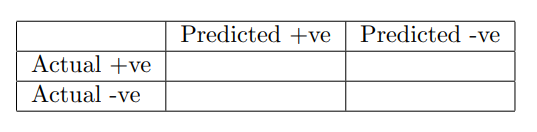
Which of the following classifiers should be chosen to maximize the recall?
Answer :-
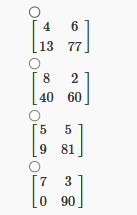
5. For the confusion matrices described in Q4, which of the following classifiers should be chosen to minimize the False Positive Rate?
Answer :-
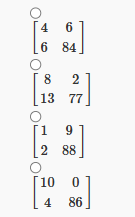
6. For the confusion matrices described in Q4, which of the following classifiers should be chosen to maximize the precision?
Answer :- For Answers Click Here
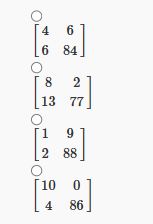
7. For the confusion matrices described in Q4, which of the following classifiers should be chosen to maximize the F1-score?
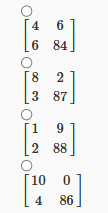
Answer :-
8. Which of the following statement(s) regarding boosting is/are correct?
- Boosting is an example of an ensemble method
- Boosting assigns equal weights to the predictions of all the weak classifiers
- Boosting may assign unequal weights to the predictions of all the weak classifiers
- The individual classifiers in boosting can be trained parallelly
- The individual classifiers in boosting cannot be trained parallelly
Answer :-
9. Which of the following statement(s) about bagging is/are correct?
- Bagging is an example of an ensemble method
- The individual classifiers in bagging can be trained in parallel
- Training sets are constructed from the original dataset by sampling with replacement
- Training sets are constructed from the original dataset by sampling without replacement
- Bagging increases the variance of an unstable classifier.
Answer :-
10. Which of the following statement(s) about ensemble methods is/are correct?
- Ensemble aggregation methods like bagging aim to reduce overfitting and variance
- Committee machines may consist of different types of classifiers
- Weak learners are models that perform slightly worse than random guessing
- Stacking involves training multiple models and stacking their predictions into new training data
Answer :- For Answers Click Here

