NPTEL Reinforcement Learning Week 12 Assignment Answers 2025
1. Consider an environment in which an agent is randomly dropped into either state s1 or s2
initially with equal probability. The agent can only view obstacles present immediately to the North, South, East or West. However the observation made in each direction by the agent may be wrong with a probability of 0.1. If in state s1 obstacles are present to the North and South, and in s2 obstacles are present to the East and West, what is the probability of the agent being in state s1 if the observation made is that there are obstacles present to the North, South and West.
- 81/82
- 41/82
- 73/82
- None of the above.
Answer :- For Answers Click Here
2. In the same environment as Question 1, suppose state s1 has obstacles present only to the North and South, and s2 has obstacles present only to the East and West. What is the probability of the agent being in state s1 if the observation made is that there are obstacles present only to the North and East.
- 81/82
- 41/82
- 73/82
- None of the above.
Answer :-
3. Assertion: One of the reasons history based methods are not feasible in certain scenarios is the significant increase in state space when trajectory lengths are large.
Reason: The number of states increases polynomially w.r.t. trajectory length.
- Both Assertion and Reason are true, and Reason is correct explanation for Assertion.
- Both Assertion and Reason are true, but Reason is not correct explanation for assertion
- Assertion is true, Reason is false
- Both Assertion and Reason are false
Answer :-
4. Suppose that we solve a POMDP using a Q-MDP like solution discussed in the lectures – where we assume that the MDP is known and solve it to learn Q values for the true (state, action) pairs. Which of the following are true?
- We can recover a policy for execution in the partially observable environment by weighting Q values by the belief distribution bel so that π(s)=argmaxa∑sbel(s)Q(s,a).
- We can recover an optimal policy for the POMDP from the Q values that have been learnt for the true (state, action) pairs.
- Policies recovered from Q-MDP like solution methods are always better than policies learnt by history based methods.
- None of the above
Answer :-
5. Consider the grid-world shown below:
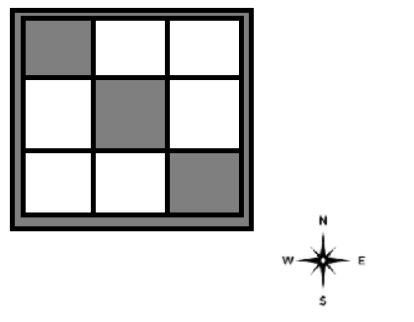
Walls and obstacles are colored gray. The agent is equipped with a sensor that can detect the presence of walls or obstacles immediately to its North, South, East or West.
Which of the following are true if we represent states by their sensor observations?
- The grid-world is a 1st-order Markov system.
- The grid-world is a 2nd-order Markov system.
- The grid-world is a 3rd-order Markov system.
- The grid-world is a 4th-order Markov system.
Answer :- For Answers Click Here

