NPTEL Reinforcement Learning Week 3 Assignment Answers 2025
1. Consider the following policy-search algorithm for a multi-armed binary bandit:
∀a,πt+1(a)=πt(a)(1−α)+α(1a=atrt+(1−1a=at)(1−rt))where 1at=a is 1 if a=at and 0 otherwise. Which of the following is true for the above algorithm?
- It is LR−I algorithm.
- It is LR−ϵP algorithm.
- It would work well if the best arm had the probability of 0.9 of resulting in +1 reward and the next best arm had a probability of 0.5 of resulting in +1 reward
- It would work well if the best arm had the probability of 0.3 of resulting in +1 reward and the worst arm had a probability of 0.25 of resulting in +1 reward
Answer :- For Answers Click Here
2. Assertion: Contextual bandits can be modeled as a full reinforcement learning problem.
Reason: We can define an MDP with the set of states being the set of possible contexts. The set of actions available at each state correspond to the arms in the contextual bandit problem, with every action leading to the termination of the episode and the agent getting a reward depending on the context and the selected arm.
- Assertion and Reason are both true and Reason is a correct explanation of Assertion
- Assertion and Reason are both true and Reason is not a correct explanation of Assertion
- Assertion is true and Reason is false
- Both Assertion and Reason are false
Answer :-
3. Which of the following expressions is a possible update made when using REINFORCE for the following policy? π(a1;θ)=sin2(θ), consider only two actions, a1 and a2 are possible. Consider α
can be taken to be any constant (Any constant obtained in the expression can be absorbed into α).
- α(R−b)cot(θ)
- −α(R−b)tan(θ)
- Neither (a) or (b)
- Both (a) and (b)
Answer :-
4. Let’s assume for some full RL problem we are acting according to a policy π. At some time t, we are in a state s where we took action a1. After few time steps, at time t’, the same state s was reached where we performed an action a2(≠a1). Which of the following statements is true?
- π is definitely a stationary policy
- π is definitely a non-stationary policy
- π can be stationary or non-stationary.
Answer :-
5. Which of the following statements is true about the RL problem?
- We assume that the agent determines the reward based on the current state and action
- Our main aim is to maximize the current reward.
- The agent performs the actions in a deterministic fashion.
- It is possible to have zero rewards.
Answer :-
6. Which of the following is the minimal representation needed to accurately represent the value function, given we are performing actions in a 2nd-order Markov process? (si represents the state at ith step in an MDP)
- V(si)
- V(si,si+1)
- V(si,si+1,si+2)
- V(si,si+1,si+2,si+3)
Answer :- For Answers Click Here
7.
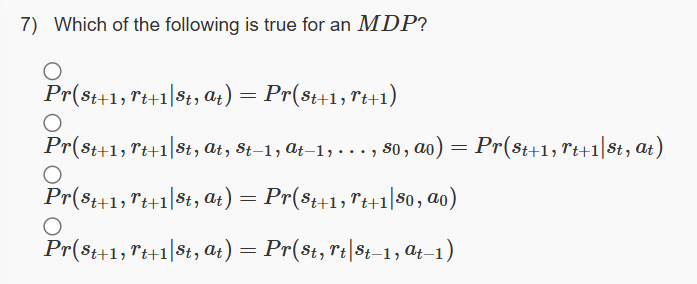
Answer :-
8. Let us say we are taking actions according to a Gaussian distribution with parameters μ and σ. We update the parameters according to REINFORCE and at denote the action taken at step t.
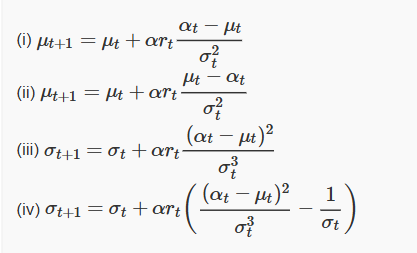
Which of the above updates are correct?
- (i), (iii)
- (i), (iv)
- (ii), (iii)
- (ii), (iv)
Answer :-
9.

Answer :-
10. Remember for discounted returns,
Gt=rt+γrt+1+γ2rt+2+....Where γ is a discount factor. Which of the following best explains what happens when γ=0?
- The rewards will be farsighted.
- The rewards will be nearsighted.
- The future rewards will have more weightage than the immediate reward.
- None of the above is true.
Answer :- For Answers Click Here

