NPTEL Reinforcement Learning Week 7 Assignment Answers 2025
1. Assertion: TD(1), a way of implementing Monte Carlo with eligibility traces, extends Monte Carlo algorithm for continuing tasks.
Reason: TD(1), implemented with eligibility traces, is an offline algorithm
- Assertion and Reason are both true and Reason is a correct explanation of Assertion
- Assertion and Reason are both true and Reason is not a correct explanation of Assertion
- Assertion is true and Reason is false
- Both Assertion and Reason are false
Answer :- For Answers Click Here
2. In solving the control problem, suppose that the first action that is taken is not an optimal action according to the current policy at the start of an episode. Would an update be made corresponding to this action and the subsequent reward received in Watkin’s Q(λ) algorithm?
- Yes
- No
Answer :-
3.
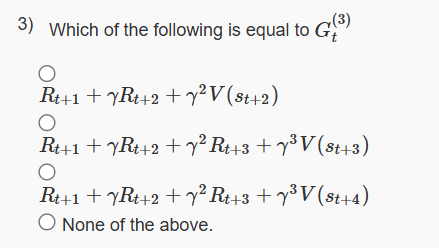
Answer :-
4. Considering episodic tasks and for λ∈(0,1) , it is not necessarily true that the one-step return always gets assigned the maximum weight in the λ -return?
- yes
- no
Answer :-
5.

Answer :-
6.

Answer :- For Answers Click Here
7. Consider the current state is s and the action recommended by the policy, a1, is taken. The possible reason(s) behind setting ∀a≠a1,Et(s,a)=0, is/are:
(i) Rewards obtained by taking a1 in s should not be attributed to actions other than a1 taken when in state s previously.
(ii) It assumed that the time steps between reaching s are large enough to decay the eligibility trace to 0.
Which of the above is/are the correct reason(s)?
- Only (i)
- Only (ii)
- Both (i) and (ii)
- None of the above
Answer :-
8. Assertion: When using an ϵ -greedy exploration strategy, and Watkins Q(λ), the ϵ value must be kept low. Reason: Traces will become too short if a high value of ϵ is used, negating many of the advantages of using eligibility traces.
- Both Assertion and Reason are true, and Reason is correct explanation for Assertion
- Both Assertion and Reason are true, but Reason is not correct explanation for assertion
- Assertion is true, Reason is false
- Both Assertion and Reason are false
Answer :-
9. Consider the following trajectory: s3,s2,s1,s2,s3,s4,s5,s6. What would be the eligibility value E8(s2), for state s2 after the 8th time step if we use accumulating trace. Discount factor = γ, trace decay parameter = λ, initial value of eligibility is zero for all states.
γ2λ2
γ8λ8
γ3λ3(γ2λ2+2)
γ4λ4(γ3λ3+γλ+1)
Answer :-
10.

Answer :- For Answers Click Here

