NPTEL Reinforcement Learning Week 9 Assignment Answers 2025
1. State True or False for the following statements:
Statement 1: DQN is an on-policy technique.
Statement 2: Actor-Critic is a policy gradient method.
- Both the statements are True.
- Statement 1 is True and Statement 2 is False.
- Statement 1 is False and Statement 2 is True.
- Both the statements are False.
Answer :- For Answers Click Here
2. What are the reasons behind using an experience replay buffer in DQN?
- Random sampling from experience replay buffer breaks correlations among transitions.
- It leads to efficient usage of real-world samples.
- It guarantees convergence to the optimal policy.
- None of the above
Answer :-
3. Statement: DQN is implemented with current and target network.
Reason: Using target network helps in avoiding chasing a non-stationary target.
- Both Assertion and Reason are true, and Reason is correct explanation for Assertion.
- Both Assertion and Reason are true, but Reason is not correct explanation for assertion.
- Assertion is true, Reason is false
- Both Assertion and Reason are false
Answer :-
4. Policy gradient methods can be used for continuous action spaces.
- True
- False
Answer :-
5. Assertion: Actor-critic updates have lesser variance than REINFORCE updates.
Reason: Actor-critic methods use TD target instead of Gt
- Both Assertion and Reason are true, and Reason is correct explanation for Assertion.
- Both Assertion and Reason are true, but Reason is not correct explanation for assertion.
- Assertion is true, Reason is false
- Both Assertion and Reason are false
Answer :-
6. Choose the correct statement for Policy Gradient Theorem for average reward formulation:
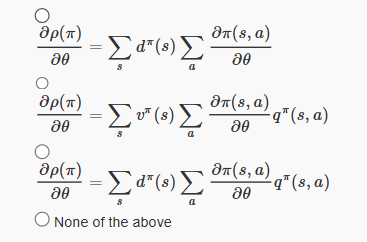
Answer :- For Answers Click Here
7. Suppose we are using a policy gradient method to solve a reinforcement learning problem. Assuming that the policy returned by the method is not optimal, which among the following are plausible reasons for such an outcome?
- The search procedure converged to a locally optimal policy
- The search procedure was terminated before it could reach an optimal policy.
- An optimal policy could not be represented by the parameterisation used to represent the policy.
- None of these
Answer :-
8. State True or False:
Monte Carlo policy gradient methods typically converge faster than the actor-critic methods, given that we use similar parameterisations and that the approximation to the Qπ used in the actor-critic method satisfies the compatibility criteria.
- True
- False
Answer :-
9. When using policy gradient methods, if we make use of the average reward formulation rather than the discounted reward formulation, then is it necessary to assign a designated start state, s0 ?
- Yes
- No
- Can’t say
Answer :-
10. State True or False:
Exploration techniques like softmax (or other equivalent techniques) are not needed for DQN as the randomisation provided by experience replay provides sufficient exploration.
- True
- False
Answer :- For Answers Click Here

